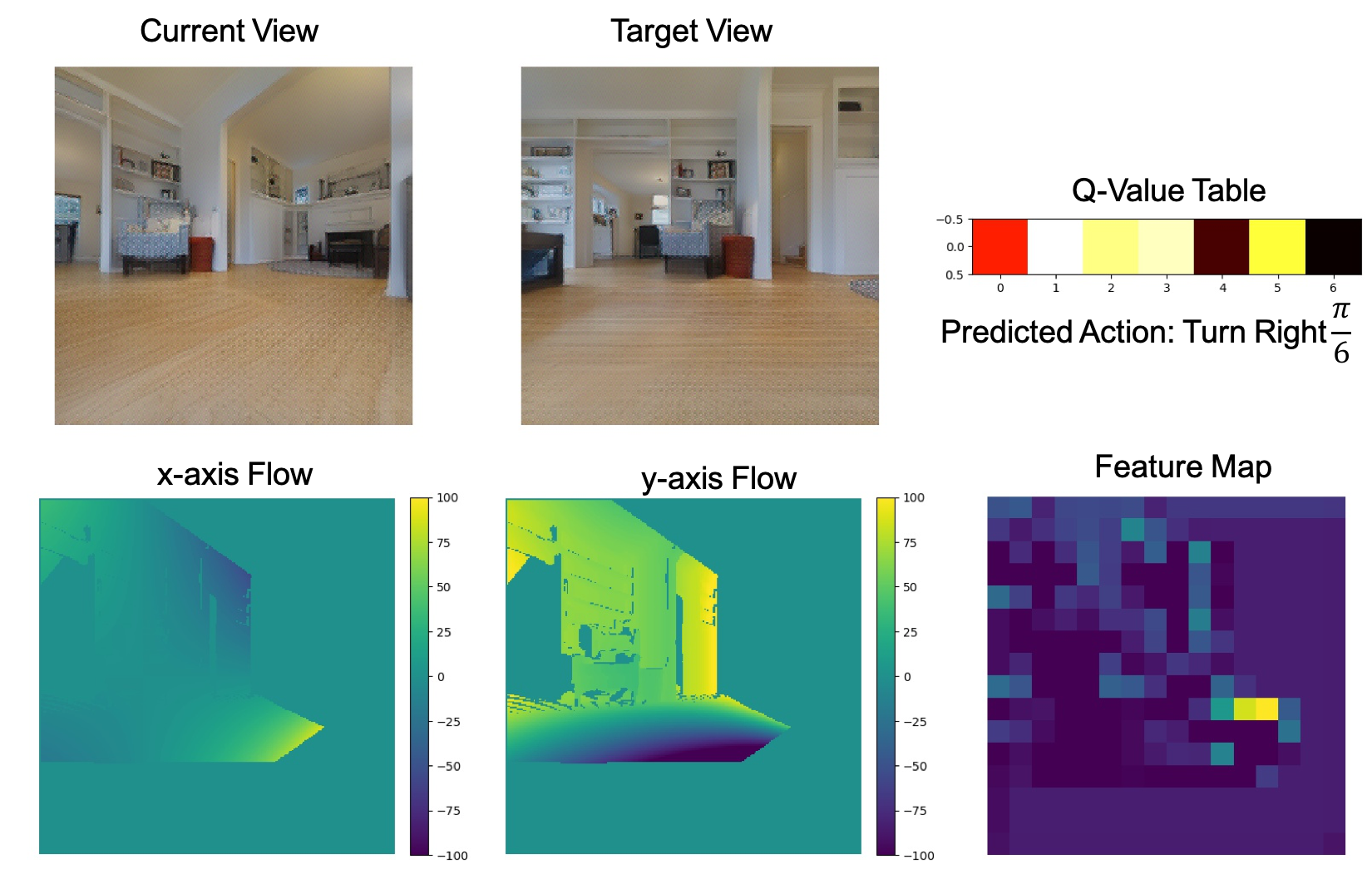
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
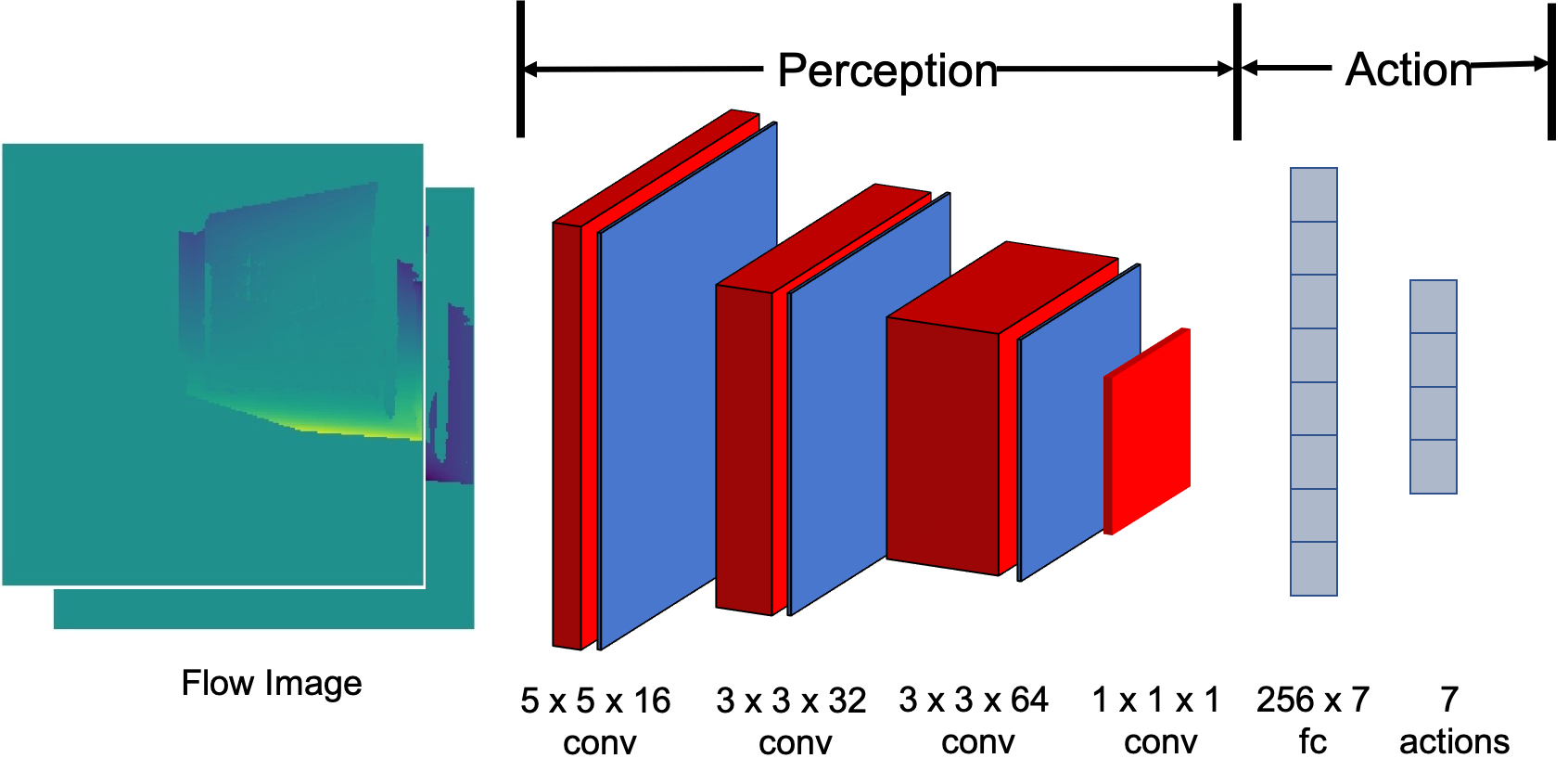
|
|
|
|
|
|
|
@inproceedings{li2020learning,
title={Learning view and target invariant visual servoing for navigation},
author={Li, Yimeng and Ko{\v{s}}ecka, Jana},
booktitle={2020 IEEE International Conference on Robotics and Automation (ICRA)},
pages={658--664},
year={2020},
organization={IEEE}
}
|
AcknowledgementsWe thank members of the GMU Vision and Robotics Lab.This webpage template was borrowed from some colorful folks. |