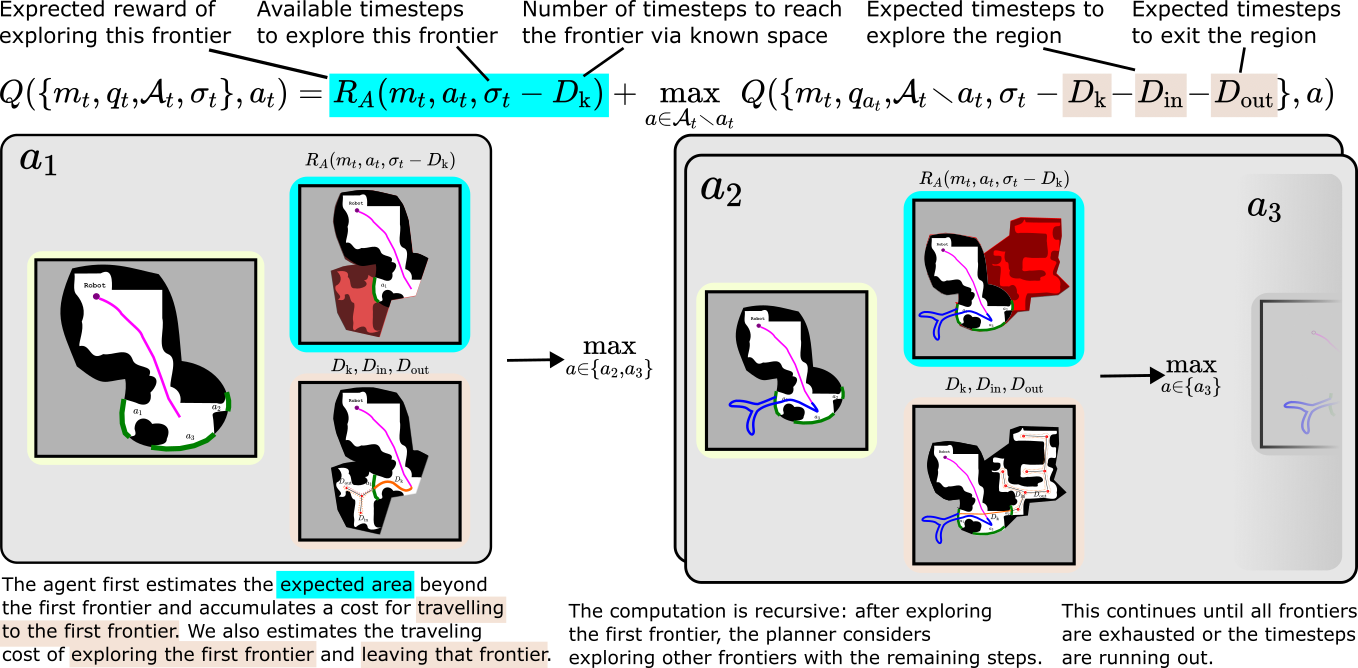
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
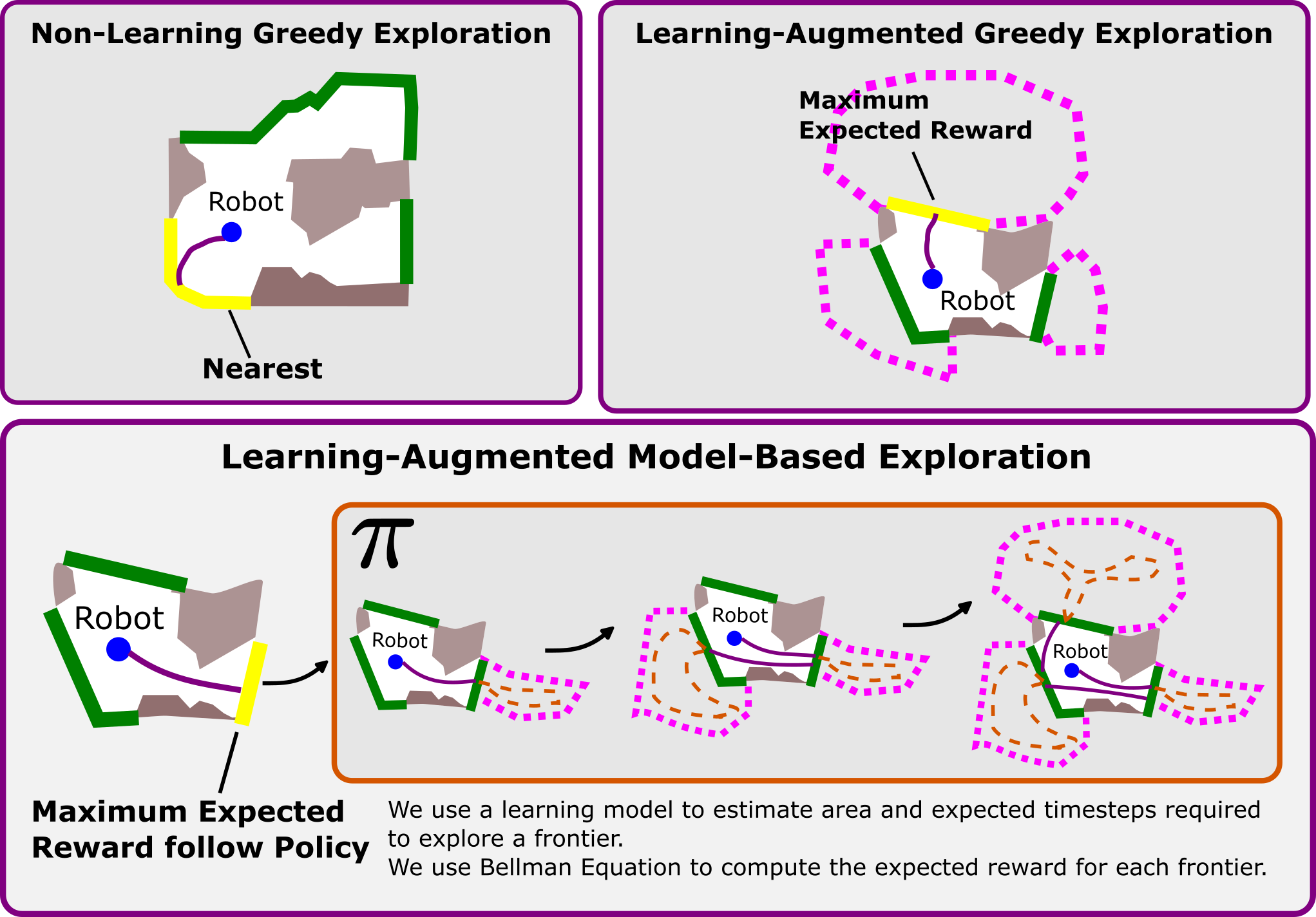
| At each step, the agent will receive a 360 panorama or 90 degree egocentric observation. Here in the video, we show a running example of our model exploring a novel scene using a frontier-based approach. A frontier is a boundary between free and unknown space, as denoted by the green pixels in the video. Yellow pixels are the selected frontier. |
|
|
|
|

|
|
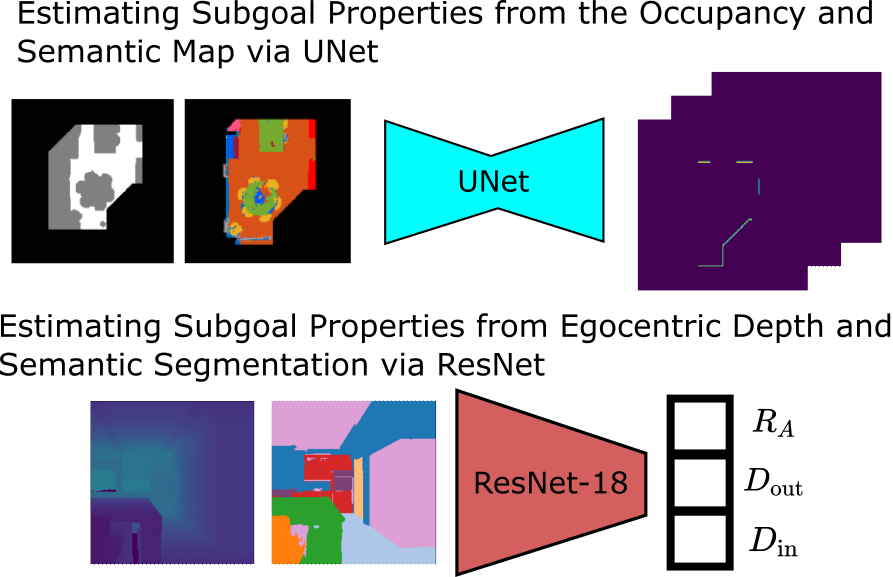
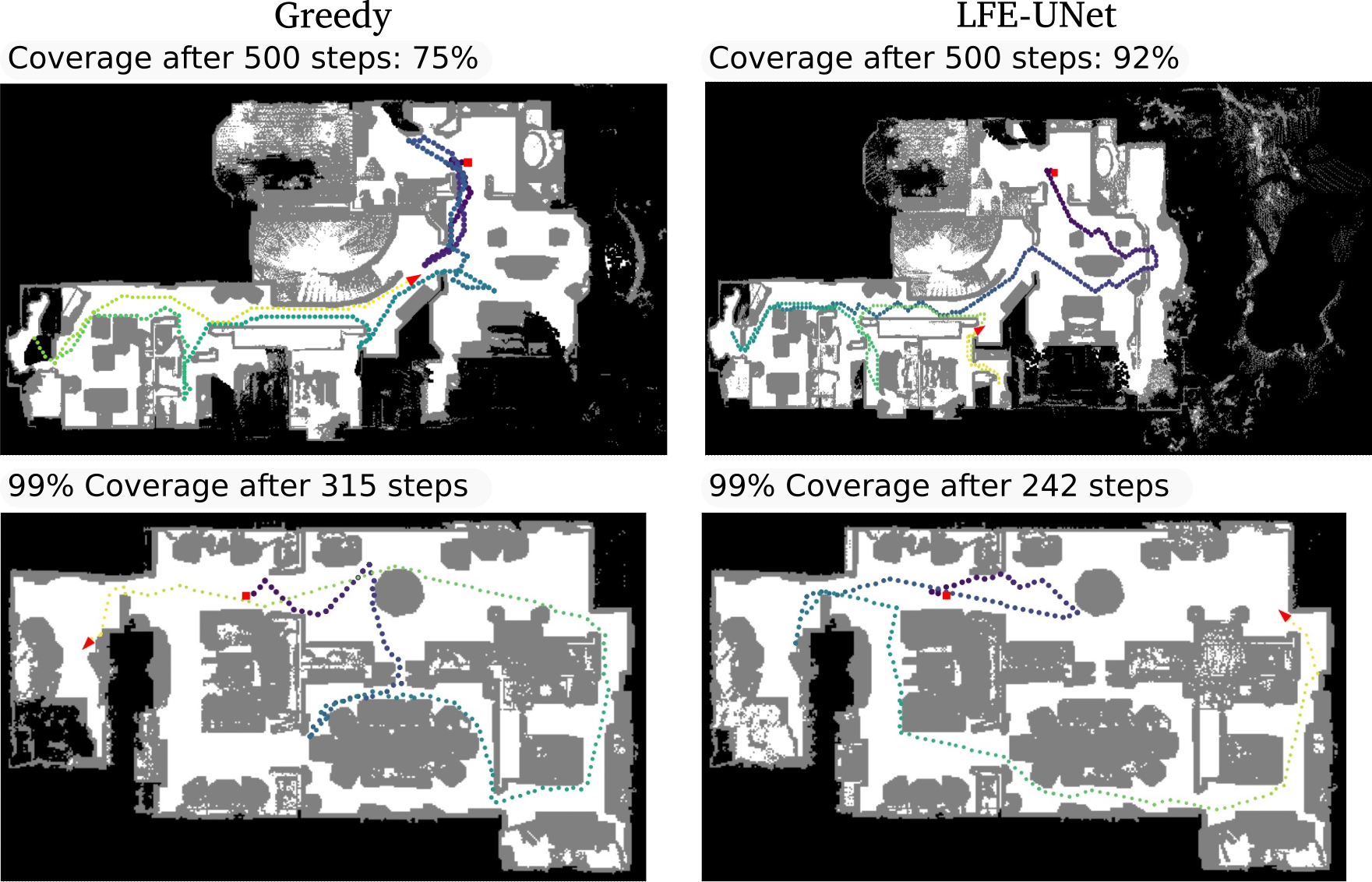
For the map based model, We use a U-net architecture where the input to the U-Net model is the currently observed occupancy and semantic map. For the view based model, the input to the ResNet-18 model is the egocentric depth and semantic observation. |
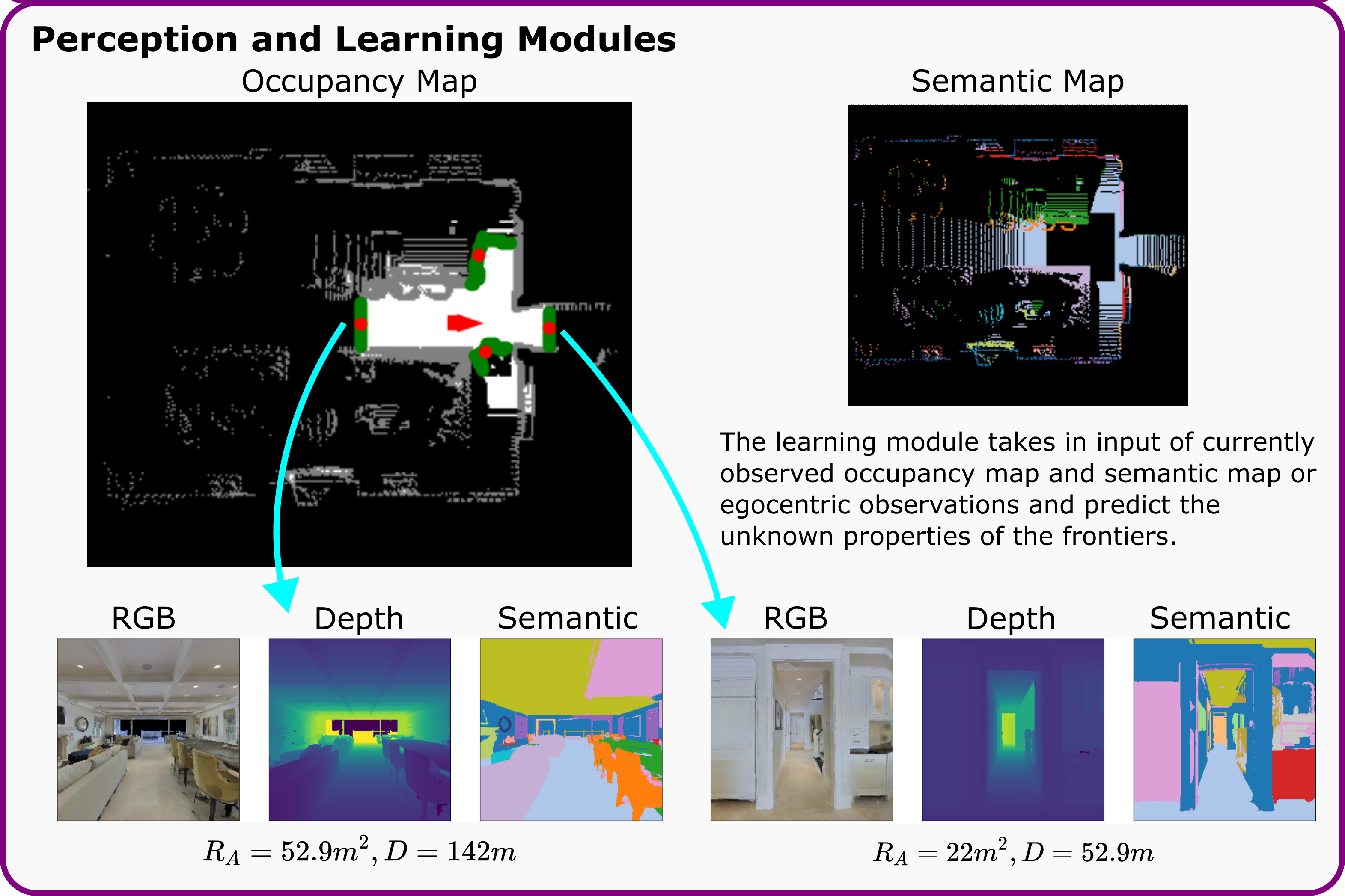
|
|
@inproceedings{li2023learning,
title={Learning-augmented model-based planning for visual exploration},
author={Li, Yimeng and Debnath, Arnab and Stein, Gregory J and Ko{\v{s}}eck{\'a}, Jana},
booktitle={2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages={5165--5171},
year={2023},
organization={IEEE}
}
|
AcknowledgementsWe thank members of the GMU Vision and Robotics Lab and RAIL.This webpage template was borrowed from some colorful folks. |