|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
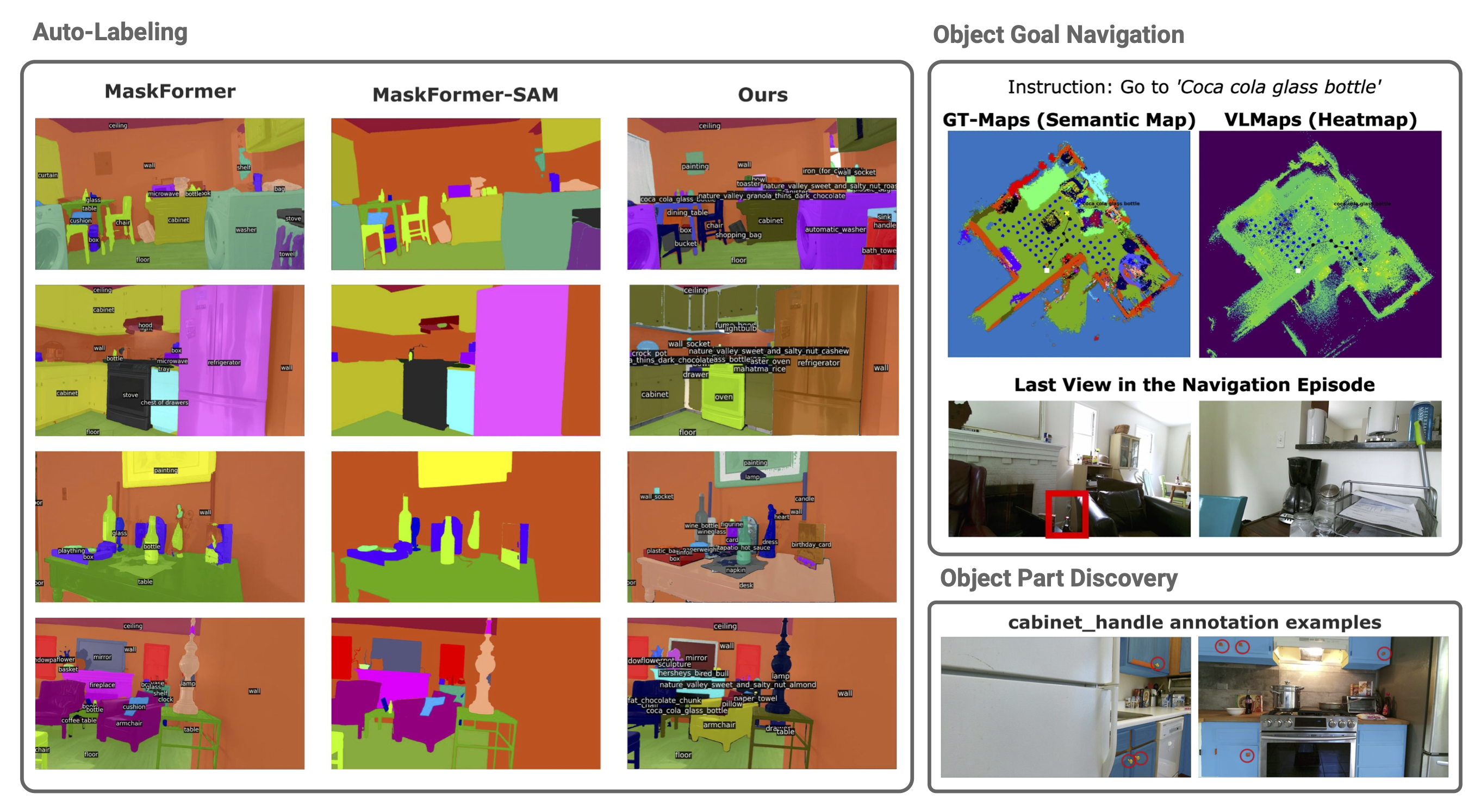
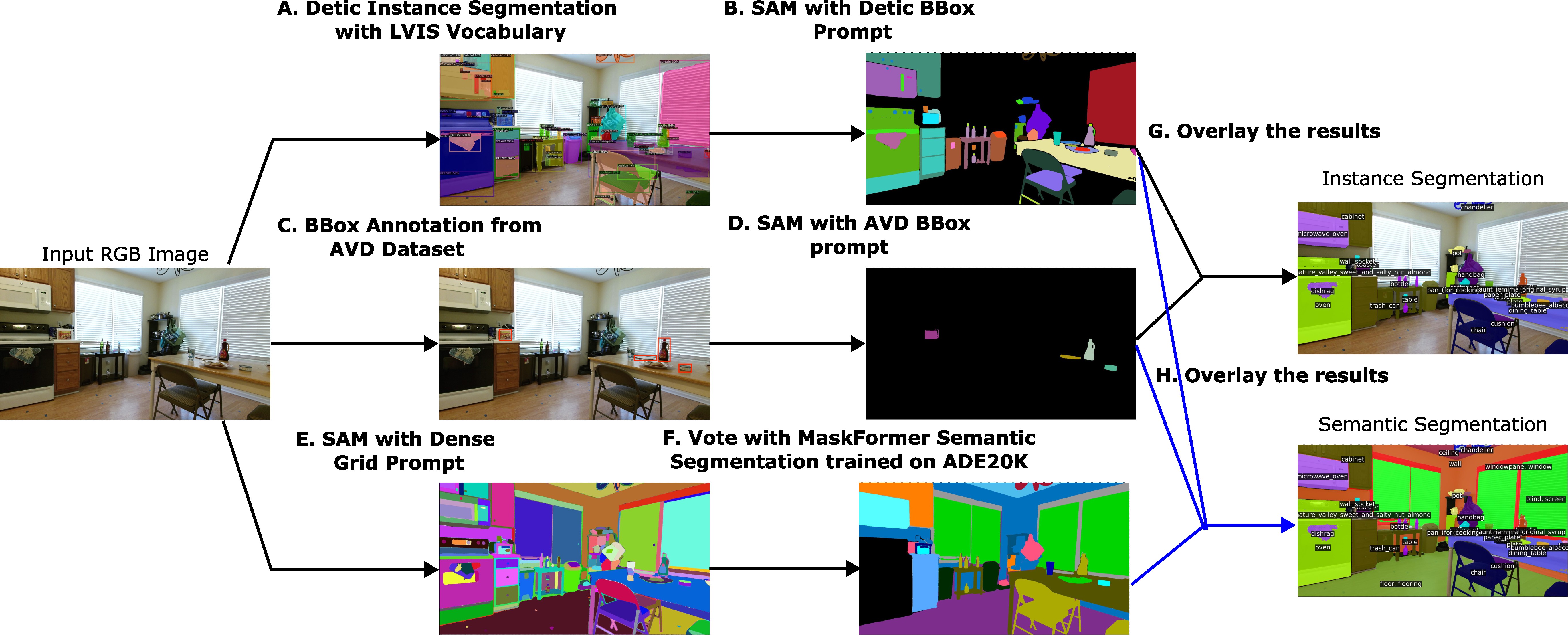
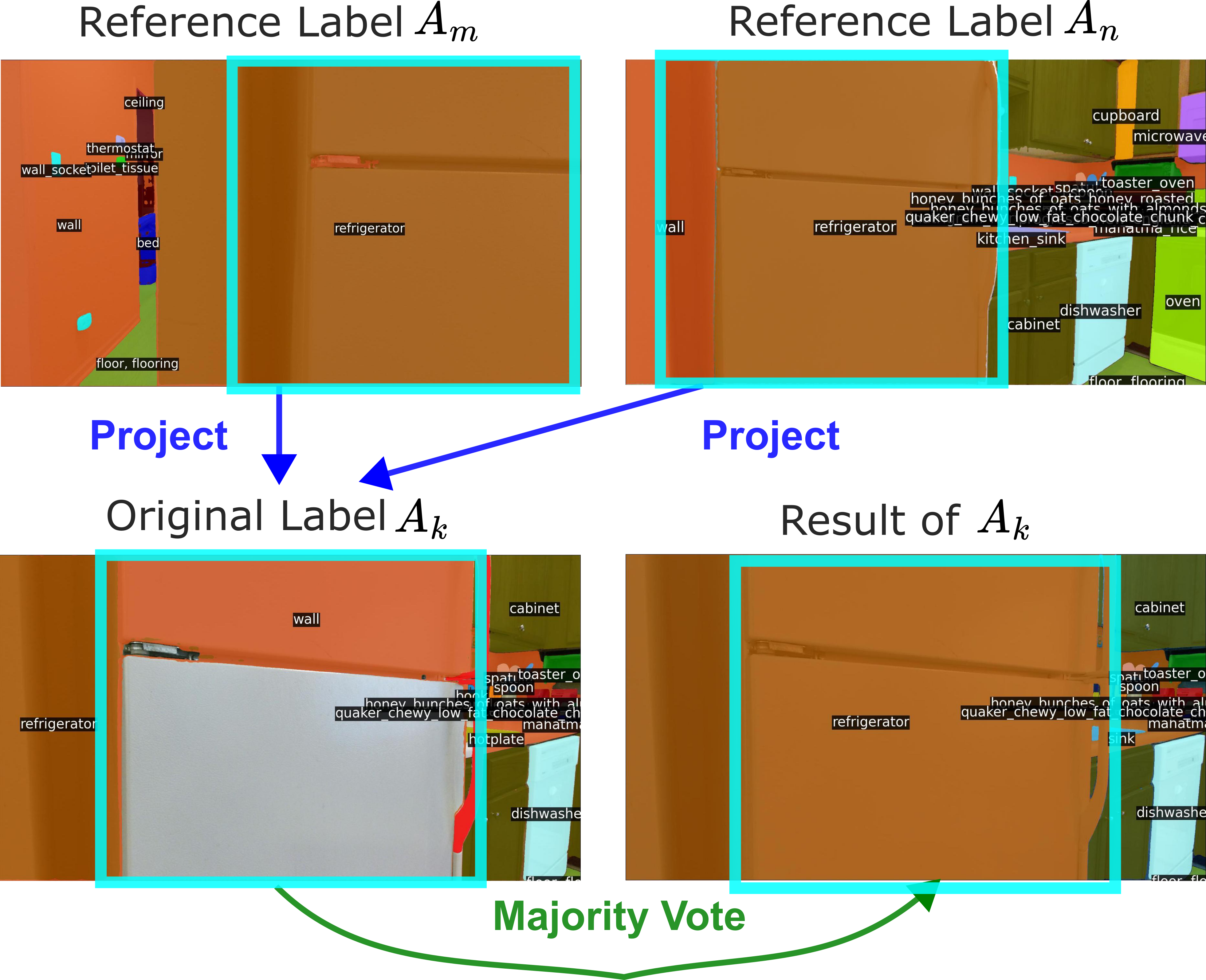
| Starting from an RGB-D dataset, we propose a labeling approach for semantic segmentation annotations. On top of the semantic segmentation results, we additionally proposed two downstream tasks for robot navigation. We build top-down-view semantic maps and use them for zero-shot semantic-goal navigation. We proposed an object part segmentation task for the ’cabinet handle’ related to the robot mobile manipulation task. |
|

|

|
|
|

|

|
@inproceedings{li2024labeling,
title={Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models},
author={Li, Yimeng and Rajabi, Navid and Shrestha, Sulabh and Alimoor, Reza and Ko{\v{s}}eck{\'a}, Jana},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={578--587},
year={2024}
}
|
AcknowledgementsWe thank members of the GMU Vision and Robotics Lab.This webpage template was borrowed from some colorful folks. |